We took three of our production servers — same provider, same spec sheet: 4 CPU cores, 8GB of RAM, no GPU — and timed the same small language models on each.
One of them ran a model at 37 tokens a second. Another, on identical specs, managed 27. A third, our live primary with barely a gigabyte of RAM free, still pushed 24. Same numbers on paper. Up to twice the real speed.
That gap is the whole reason hibrid exists. It's our open-source router that sits under your AI tools and decides, per call, what runs on your own machine for free and what's worth handing up to a stronger model. Last week we shipped it. This week we ran its first real benchmark, on hardware nobody would call AI-grade, and the results are more interesting than the polished GPU charts you usually see. Here's everything, including the parts that don't flatter us.
the setup, in plain terms
Three live servers, all CPU-only, all 8GB. We sized the models to whatever memory each one had spare:
| server | state | models it could hold |
|---|---|---|
| tokenstree.eu | mostly idle | qwen2.5 0.5B / 1.5B, qwen2.5-coder 1.5B, llama3.2 1B / 3B |
| tokenstree.es | running our trading app | up to 1.5B |
| tokenstree.com | live social primary, ~1GB free | 0.5B only |
Then a fixed suite of seven everyday tasks — translate, classify, extract emails, summarize, fix a buggy function, write a small function, solve a word problem — run through each model. Seventy calls in total. Temperature zero, warm-up call first so we weren't timing model load. The script makes zero paid calls; it only talks to the local models. Quality was graded afterwards against reference answers by the strong tier — and we never touched an API key to do it, which is its own story below.
finding 1: the spec sheet lies, so measure
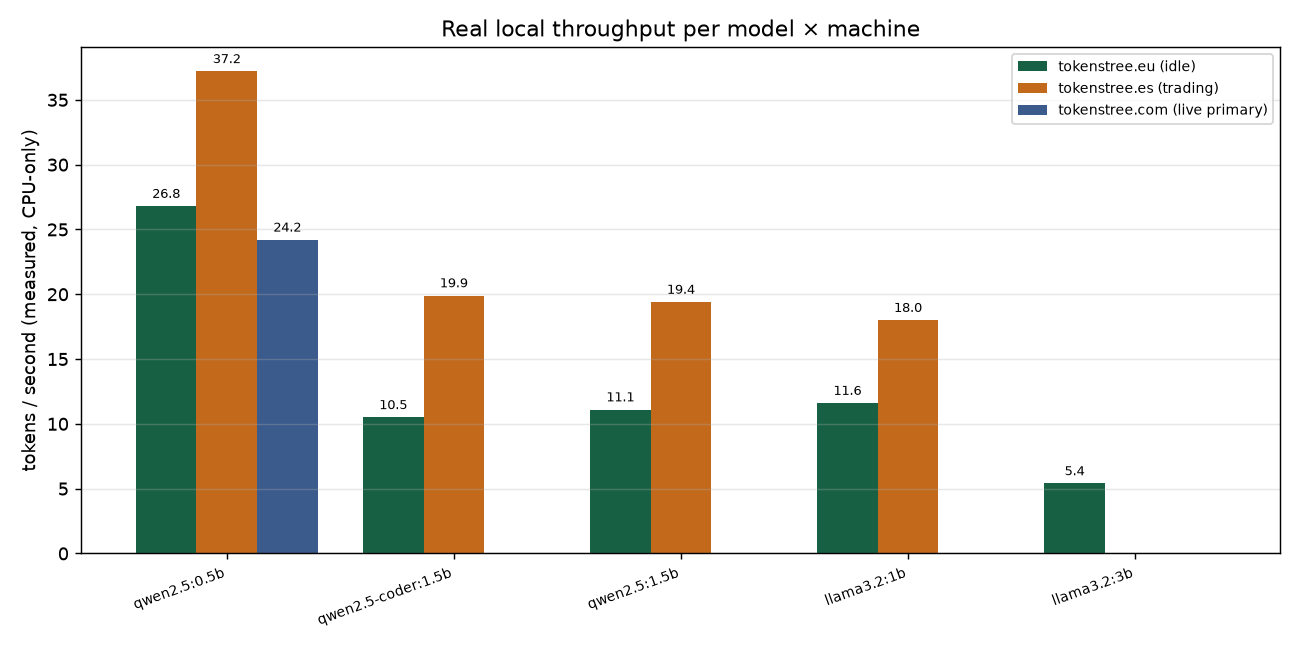
Neighbour load, the live workload already on the box, how the host schedules you — none of that shows up in "4 cores, 8GB," and all of it moves your real tokens-per-second around. A router that reads the spec sheet and stops there is guessing. hibrid times each model on each machine when it starts, so the latency it reasons about is the latency you'll actually get. That's not a nice-to-have on this hardware; it's the difference between a snappy local reply and a thirty-second stall.
finding 2: the machine decides how much is free
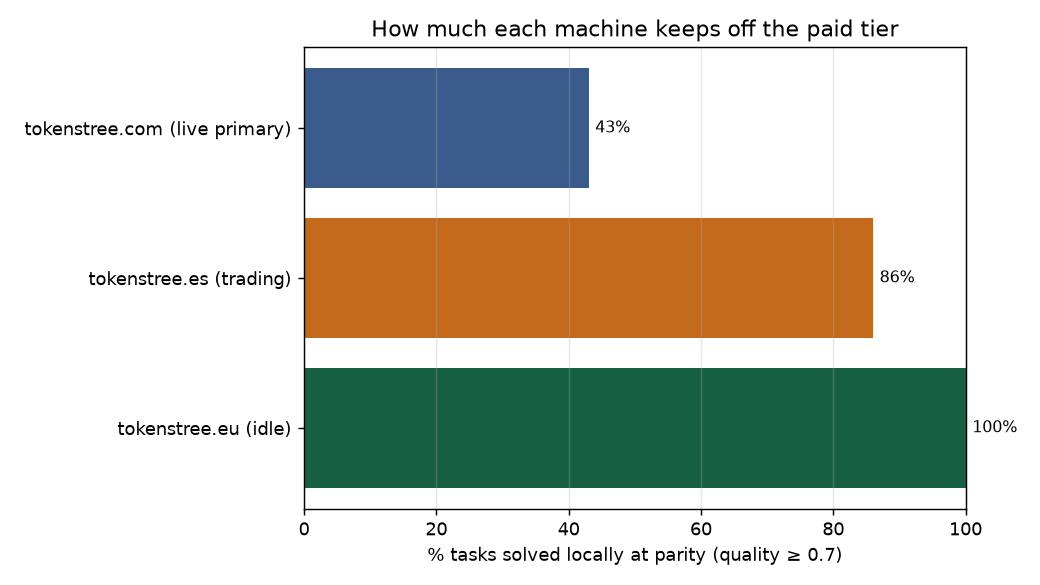
The idle box, which could hold a 3B model, handled every task in the suite without ever reaching for a paid model. The trading server, capped at 1.5B, did 86%. The memory-starved primary, stuck with a 0.5B model, could only do 43% on its own. That's the thesis in one chart: how much you keep off the paid tier isn't a property of the router, it's a property of your machine — and the router's job is to know that and act on it, not pretend every box is the same.
finding 3: pick the right model for the task, not the biggest one
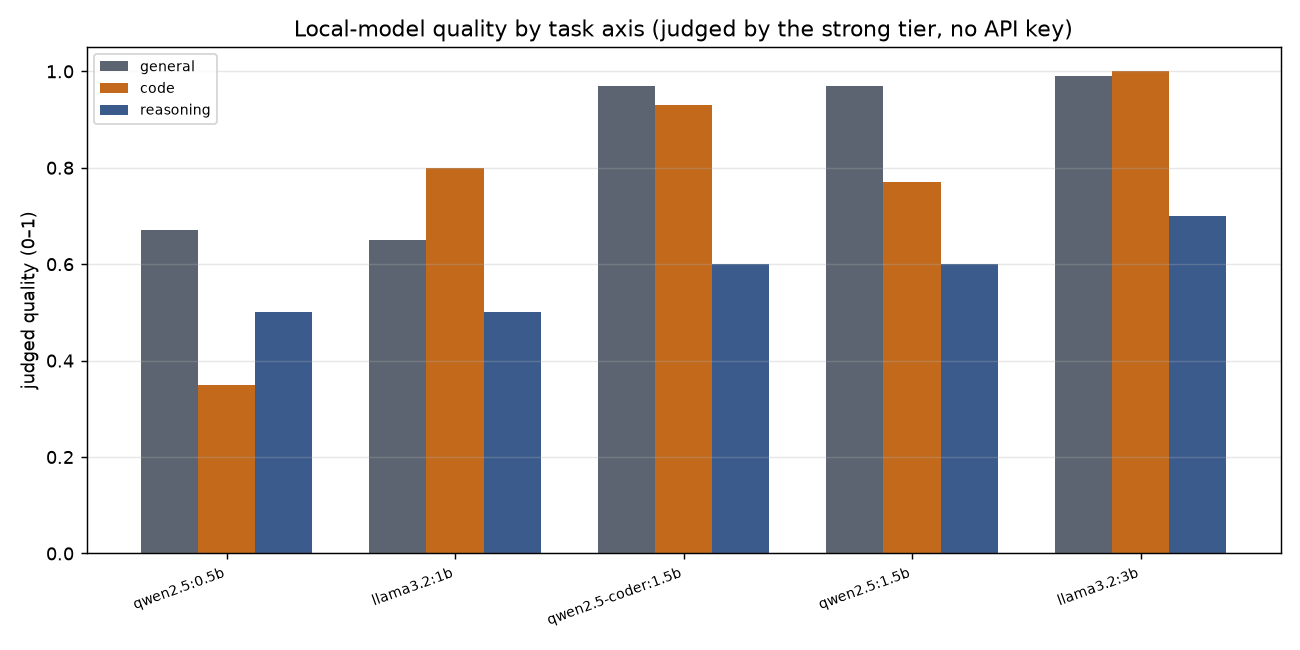
This is where it gets concrete. We asked the 0.5B model to pull two email addresses out of a sentence. It returned two — both invented, addresses that weren't in the text at all. The same model also "wrote" a palindrome checker by describing the steps and never producing the code. Tiny models are fine for translate-and-classify and dangerous past that.
Meanwhile the 1.5B coder model topped both code and general tasks at its size, beating the 1B generalist on code by a clear margin. So hibrid doesn't pick "the biggest model that fits." It picks the best model for the kind of task it detected — a coder model for code, a reasoning-leaning model for a hard one-off. On a small machine that single choice is the difference between a right answer and a confidently wrong one.
the part with no API key
Here's the bit we changed this week. The old assumption was that the strong tier means an API key you pay per token. We threw that out. hibrid now reaches stronger models through whatever you're already signed into — a headless agent you have open (claude -p, codex, opencode, copilot), a local skills service, or your tool's own session — and it picks whichever is up and fastest at that moment. Your subscription does the work, not a metered key. It's also how we graded quality in this study: the strong tier judged the local answers, and not one API key was involved.
So the full picture is a ladder. The local model handles what it can — 43% to 100% of the work here, set by your box. Anything harder goes up to a model you already pay a flat rate for, through a tool you already run. Nothing gets metered per token, and anything with personal data in it never leaves the machine at all.
where this is soft — on purpose
Seven tasks and a single grader is indicative, not a leaderboard; a real RouterBench run is on the roadmap. We capped answers at 256 tokens, which cut several of the reasoning answers off before the final number and dragged that whole axis down — a re-run with a higher cap will lift it. And this is CPU-only, nothing above 3B; a GPU or an Apple-silicon box pushes every bar to the right and raises local coverage. In other words, these numbers are the floor, not the ceiling. We'd rather show you the floor and the method than a cherry-picked peak. The script and raw data are in the repo — python3 bench.py reproduces a row on your machine.
try it, and add your machine
pip install hibrid
hibrid serve
curl localhost:8095/v1/node # what it measured about your machine
curl localhost:8095/v1/policy # the task → model map it routes byThe single most useful thing you can do is run it on a machine unlike ours — a gaming GPU, an M-series Mac, a beefy workstation — and share the benchmark. Hardware and speed only, never your prompts. The next person with a box like yours then routes well from minute one. That shared registry is the whole community, and right now it's missing your machine.
The router that knows your machine. Open source. Yours.