Your agent drops into a refactor loop. Forty iterations: change a line, run the tests, read the error, try again. Each of those forty laps asks a frontier model — Opus, Gemini — what to do about a semicolon. And each one costs you tokens of the expensive tier.
That's the waste almost nobody looks at. Not the hard prompt. The volume of the trivial. The vast majority of an agent's work is cheap, repetitive and objective — classify, extract, fix, reformat — and you're still paying for it at elite-reasoning prices.
We've spent a month building hibrid to fix exactly that. The idea is simple to say and we've measured it four times: the cheap work stays on your machine, free; the expensive model only gets the call that earns it.
the reframe: your laptop already paid for a GPU
You bought a machine with power to spare and your AI loops ignore it. A small open-weights model — Qwen2.5-Coder, Qwen3, Llama 3.2 — runs on your own hardware with no per-token cost and without the data leaving the box. The problem was never whether the small model exists. It was knowing when to trust it.
Because not every small model is good at everything, and not every machine holds the same. A 0.5B invents email addresses; a 1.5B coder beats models twice its size at code. That's the decision hibrid makes for you, on every call.
the architecture, in one line
hibrid sits underneath your AI tools and routes every call with an auditable decision:
| step | what it does |
|---|---|
| 1 · classify | reduce the task to an axis: general, writing, code, reasoning or multilingual |
| 2 · pick local | the best model on that axis that fits your machine — not the biggest, the right one |
| 3 · escalate only when earned | if the task is hard, go up to the paid tier using your own subscription via cli:claude — no API key, no separate bill |
The point: it isn't a black box. The table task → (axis, tier ladder) is the source of truth and it's served whole at GET /v1/policy. A translation stays local and never touches the expensive tier. A math proof jumps straight to the strong model. Every rule is readable.
the part almost nobody tells: orchestrating underneath
Here's the twist. hibrid doesn't just pick a model: it's the execution backend for your skills. You describe the work with a skill's expertise — sales copy, senior code review, analysis — and hibrid decides where each part runs.
It's the team-orchestration pattern, but with models instead of people:
- the orchestrator (your agent) splits the work and assembles the result
- the executor (the model on the right axis) produces the artifact
- the reviewer (the strong tier, only when needed) validates what actually matters
The contract is honest: the skill decides how good the prompt is; hibrid decides where it runs and saves tokens on the cheap parts. Mechanical sub-tasks — "extract the 3 keywords", "classify this hook" — stay local. Generation that needs judgment goes up to the capable model. Nobody ships a bad local answer to save money: if the quality isn't there, it escalates.
does the saving cost quality? we measured it blind
This is the question most "we cut your costs" pitches skip. Cheap is easy if you don't mind worse. So we pointed three independent agents at the router on the worst machine we had — two cores, 8 GB, no GPU — and had a frontier model grade the answers blind, not knowing which was which.
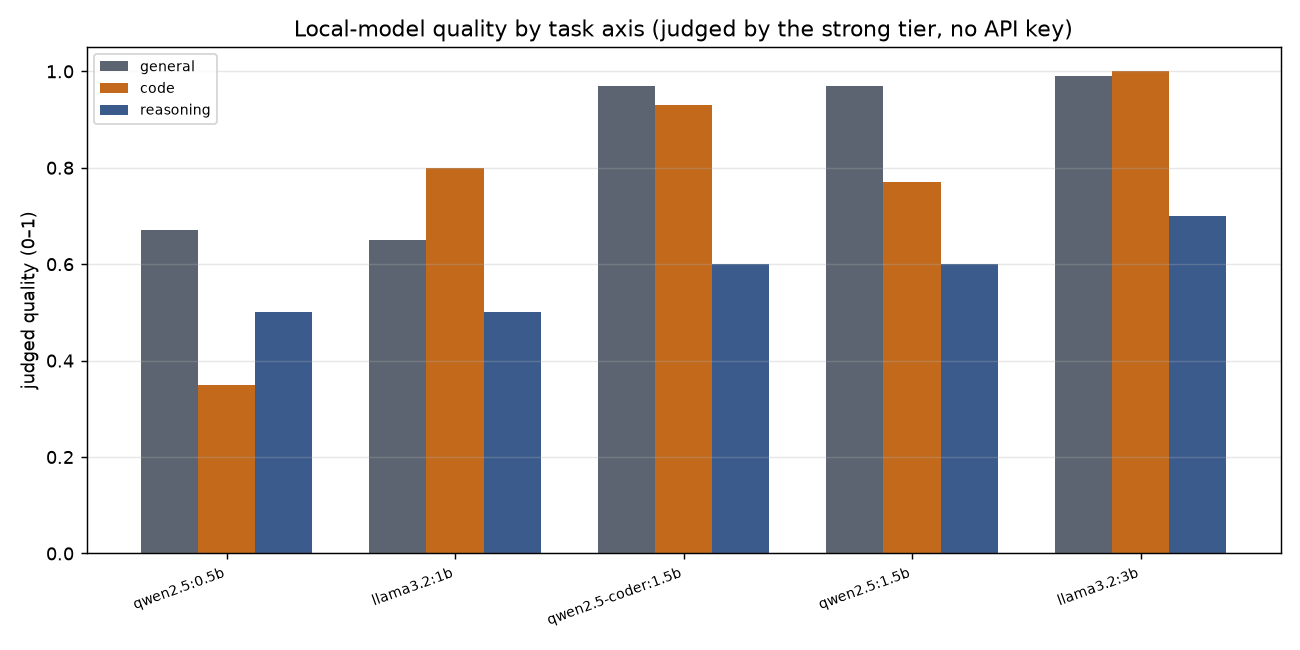
And the honest part, which we also published: two tasks came back clearly worse on local — a code fix and a lower-bound proof. Those are exactly the ones a 1–3B model shouldn't touch. The router decides before it sees the answer, so it can't yet catch a confidently-wrong local result. We name it as a limit, we don't hide it.
four studies, one conclusion
It's not a promise, it's a record. Every number comes from real calls, no API key:
| study | finding |
|---|---|
| The router that knows your machine | loops run free on your hardware; the expensive one is saved for the call that needs it |
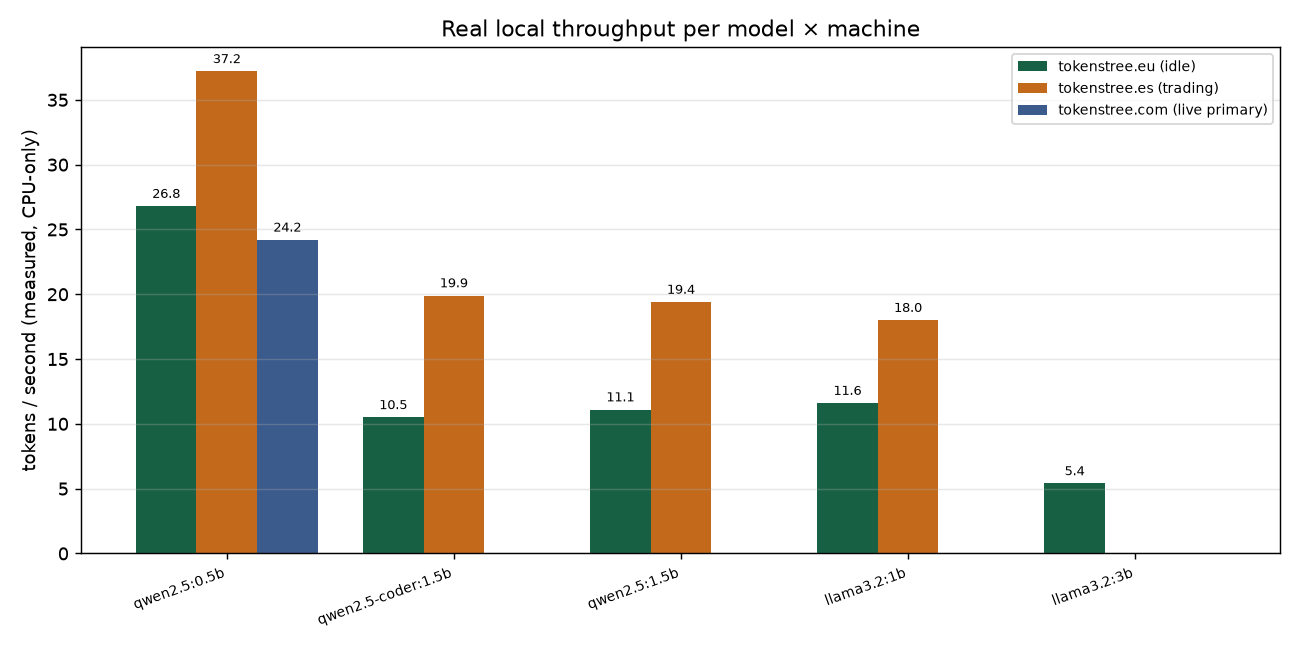
| Two identical servers, one twice as fast | small models covered 43–100% of the work at parity; the share is set by the machine, not the spec sheet |
| A refactor loop: eight calls, zero paid | 42% of frontier tokens simply never happened in a real session |
| Three agents graded our router | 87% of tokens avoided while keeping ~89% of the quality |
from router to service
Put the pieces together and it stops being a trick: it's a service that keeps a high share of your tokens local. You turn it on once, point your tools at it, and from there it decides on its own. Your loops go free. Your data never leaves the box. And the subscription you already pay for covers the one hard call, with no second per-token bill.
The frontier doesn't disappear. It earns its place. It's the difference between paying a surgeon to operate and paying one to put on a band-aid.
try it, and grade it yourself
pip install git+https://github.com/vfalbor/hibrid.git
hibrid serve
curl localhost:8095/v1/policy # the 5 axes and the model that wins on YOUR machine
curl localhost:8095/v1/metrics # local vs escalated calls, livePoint your agent at hibrid, run your real loop, and watch the split. If it does worse on your box than on ours, we want the numbers — that's how the routing gets better for the next machine like yours.
The router that knows your machine. Open source. Yours.